Union
transformation is an active and connected transformation. It is multi
input group transformation used to merge the data from multiple
pipelines into a single pipeline. Basically it merges data from
multiples sources just like the UNION ALL set operator in SQL. The union
transformation does not remove any duplicate rows.
The following rules and guidelines should be used when using a union transformation in a mapping
- Union transformation contains only one output group and can have multiple input groups.
- The input groups and output groups should have matching ports. The datatype, precision and scale must be same.
- Union transformation does not remove duplicates. To remove the duplicate rows use sorter transformation with "select distinct" option after the union transformation.
- The union transformation does not generate transactions.
- You cannot connect a sequence generator transformation to the union transformation.
- Union transformation does not generate transactions.
Creating union transformation
Follow the below steps to create a union transformation
- Go the mapping designer, create a new mapping or open an existing mapping
- Go to the toolbar-> click on Transformations->Create
- Select the union transformation and enter the name. Now click on Done and then click on OK.
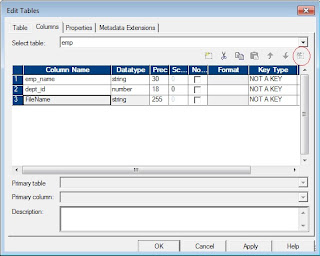
- Go to the Groups Tab and then add a group for each source you want to merge.
- Go to the Group Ports Tab and add the ports.
Components of union transformation
Configure the following tabs of union transformation
- Transformation: You can enter name and description of the transformation
- Properties: Specify the amount of tracing level to be tracked in the session log.
- Groups Tab: You can create new input groups or delete existing input groups.
- Group Ports Tab: You can create and delete ports for the input groups.
Note:
The ports tab displays the groups and ports you create. You cannot edit
the port or group information in the ports tab. To do changes use the
groups tab and group ports tab.
Why union transformation is active
Union
is an active transformation because it combines two or more data
streams into one. Though the total number of rows passing into the Union
is the same as the total number of rows passing out of it, and the
sequence of rows from any given input stream is preserved in the output,
the positions of the rows are not preserved, i.e. row number 1 from
input stream 1 might not be row number 1 in the output stream. Union
does not even guarantee that the output is repeatable.
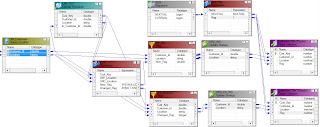
Union Transformation Example
1.
There are two tables in the source. The table names are employees_US
and employees_UK and have the structure. Create a mapping to load the
data of these two tables into single target table employees?